
1. Khái niệm khoảng biến thiên của mẫu số liệu ghép nhóm
Khoảng biến thiên, kí hiệu R, của mẫu số liệu ghép nhóm là hiệu số giữa đầu mút phải của nhóm cuối cùng và đầu mút trái của nhóm đầu tiên chứa dữ liệu của mẫu số liệu.
2. Công thức tính khoảng biến thiên của mẫu số liệu ghép nhóm
Xét mẫu số liệu ghép nhóm được cho ở bảng sau:

Nếu \({n_1}\) và \({n_k}\) cùng khác 0 thì:
\(R = {u_{k + 1}} - {u_1}\).
3. Ý nghĩa khoảng biến thiên của mẫu số liệu ghép nhóm
Khoảng biến thiên của mẫu số liệu ghép nhóm xấp xỉ cho khoảng biến thiên của mẫu số liệu gốc và có thể dùng để đo mức độ phân tán của mẫu số liệu. Khoảng biến thiên càng lớn thì mức độ phân tán càng lớn.
4. Ví dụ minh hoạ về khoảng biến thiên của mẫu số liệu ghép nhóm
1) Bảng sau thống kê cân nặng của 50 quả xoài được lựa chọn ngẫu nhiên sau khi thu hoạch ở một nông trường.

Khoảng biến thiên của mẫu số liệu ghép nhóm trên là R = 450 – 250 = 200.
2) Người ta tiến hành phỏng vấn hai nhóm khán giả về một bộ phim mới công chiếu. Nhóm A gồm những khán giả thuộc lứa tuổi 20 – 30, nhóm B thuộc lứa tuổi trên 30. Người được hỏi ý kiến phải đánh giá bộ phim bằng cách cho điểm theo một số tiêu chí nêu trong phiếu điều tra và sau đó lấy tổng số điểm (thang điểm 100). Bảng dưới đây trình bày kết quả điều tra hai nhóm khán giả:
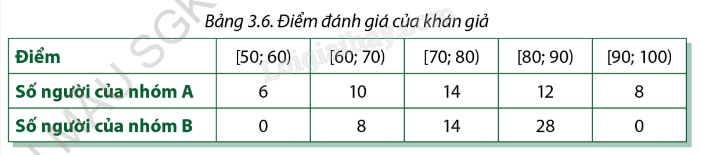
Ý kiến đánh giá của nhóm khán giả nào phân tán hơn?
Giải:
Ý kiến đánh giá của nhóm khán giả A và B lần lượt có khoảng biến thiên tương ứng là: \({R_A} = 100 - 50 = 50\); \({R_B} = 90 - 60 = 30\).
Vì \({R_A} > {R_B}\) nên ý kiến đánh giá của nhóm khán giả A phân tán hơn so với nhóm khán giả B.






Danh sách bình luận